Abstract
EXTRACT enables efficient transfer learning with RL by discovering a set of discrete, continuously parameterized skills from offline data useful for learning new tasks. EXTRACT unsupervisedly extracts a discrete set of skills from offline data that can be used for efficient learning of new tasks by: (1) Using VLMs to extract a discrete set of aligned skills from image-action data. (2) Training a skill decoder to output low-level actions given discrete skill IDs and learned continuous arguments. (3) Using the decoder, along with guidance from learned priors (see the paper), to help a skill-based policy efficiently learn new tasks with a simplified action space over skill IDs and arguments.
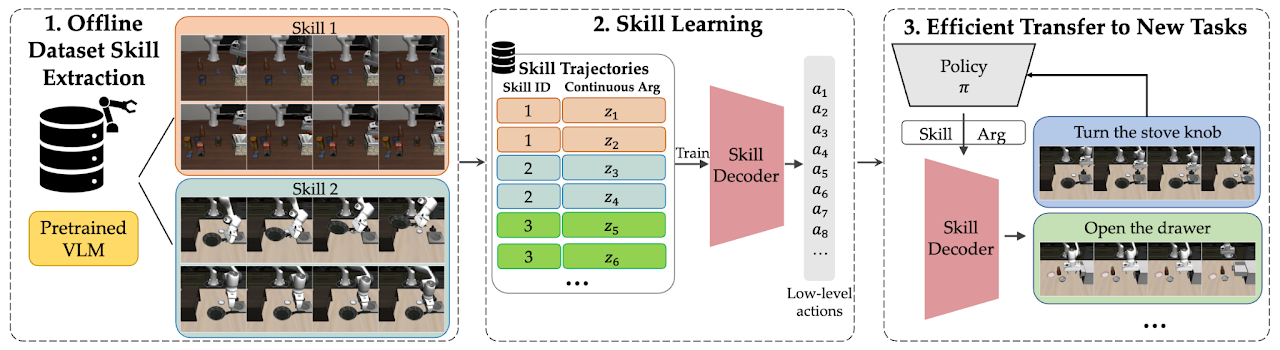
EXTRACT Method Overview
EXTRACT equips robots with a repertoire of discrete, transferable skills which can be modulated via continuous arguments to perform a wide range of tasks. It also trains priors to guide a policy in learning what skill to choose and how to use it (i.e., its continuous arguments).
Method
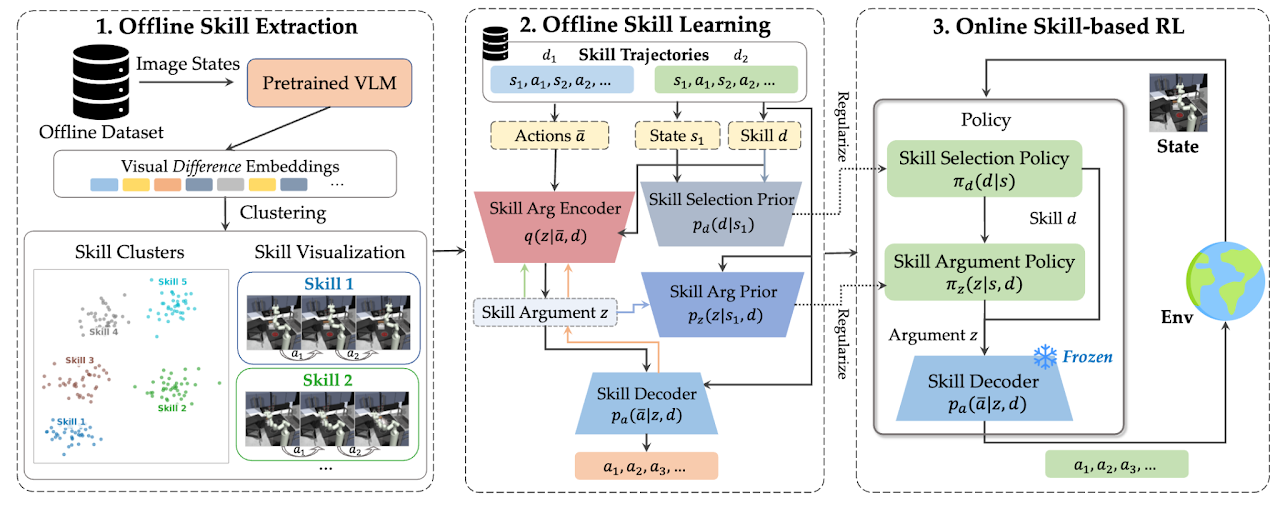
1. Offline Skill Extraction (left)
We extract a discrete set of skills from offline data by clustering together visual VLM difference embeddings representing high-level behaviors.
2. Offline Skill Learning (middle)
We train a skill decoder model, 𝒟, to output variable-length action sequences conditioned on a skill ID 𝑑 and a learned continuous argument 𝑧. The argument 𝑧 is learned by training 𝒟 with a VAE reconstruction objective from action sequences encoded by a skill encoder. Additionally, we train skill selection prior and skill argument prior to predict which skills 𝑑 and their arguments 𝑧 are useful for a given state 𝑠. Colorful arrows indicate gradients from reconstruction, argument prior, selection prior, and VAE losses.
3. Online Skill-Based RL (right)
To learn a new task, we train a skill selection and skill argument policy with reinforcement learning (RL) while regularizing them with the skill selection and skill argument priors.
Environments

We evaluate EXTRACT in two domains on 41 total tasks that require transferring knowledge to learn new skills effectively.
(a) Franka Kitchen: Franka kitchen requires executing an unseen sequence of 4 sub-tasks in a row.
(b) LIBERO: LIBERO consists of 4 unseen task suites with 10 tasks each. Each task suite tests various transfer learning capabilities.
(c) FurnitureBench: FurnitureBench is a real-world furniture assembly benchmark. We transfer learn to unseen initial object and end-effector positions and orientations.
Results
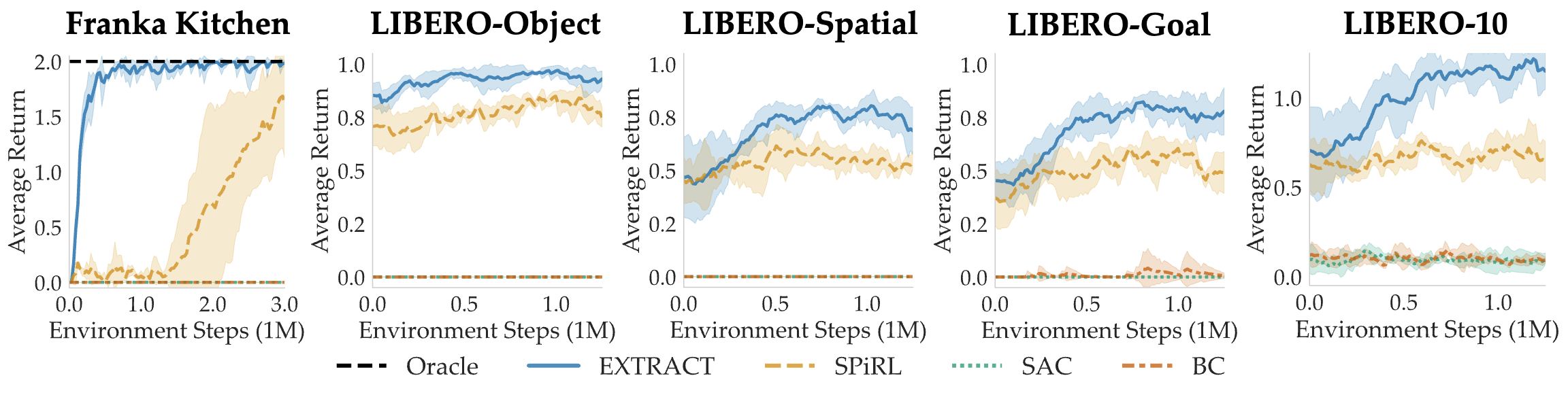
We compare EXTRACT against prior skill-based RL (SPiRL), standard SAC and RL-finetuned
BC baselines.
EXTRACT outperforms all baselines in both Franka Kitchen and LIBERO,
achieving
large sample efficiency gains of 10x over SPiRL in Franka Kitchen and
outperforming it in every LIBERO task suite.
In LIBERO-Object, Spatial, and Goal, return is equal to success rate.
Non-skill based RL baselines perform very poorly.
Franka Kitchen
Unseen sequence of 4 sub-tasks in a row not seen in the dataset.
Opens the microwave and then pushes the kettle successfully. Completes 2/4 subtasks.
Fails to successfully open the microwave door. Completes 0/4 subtasks.
Random behaviors despite being trained on the same offline dataset. Completes 0/4 subtasks.
Random behaviors as this sparse reward, image-based control task is difficult for standard RL. Completes 0/4 subtasks.
LIBERO
4 unseen task suites with 10 tasks each.
- LIBERO-Object: Different objects, same env layouts as training data.
- LIBERO-Spatial: Different spatial relationships, same objects as training data.
- LIBERO-Goal: Different goals, same objects and layouts as training data.
- LIBERO-10: Longer-horizon (two-subtask) tasks with additional varied differences from training data.
LIBERO-10 task: Put the black bowl in the bottom drawer of the cabinet and close it.
Completes 2/2 subtasks smoothly!
Fails to pick up the bowl, completes 0/2 subtasks.
Approaches the bowl but not in the right orientation, completes 0/2 subtasks.
LIBERO-10 task: Pick up the book and place it in the back compartment of the caddy.
Completes 2/2 subtasks smoothly!
Successfully completes 2/2 subtasks.
Fails to pick up the book, completes 0/2 subtasks.
FurnitureBench
We demonstrate EXTRACT's ability to transfer learn in the real-world FurnitureBench domain over just 100 trajectories of fine-tuning. The task involves assembling furniture with unseen initial object and end-effector positions and orientations.
FurnitureBench Performance Table
| Method | Before Finetuning | After Finetuning |
|---|---|---|
| SPiRL | 1.35 | 1.55 |
| EXTRACT | 1.90 | 2.50 |
BibTeX
@inproceedings{
zhang2024extract,
title={{EXTRACT}: Efficient Policy Learning by Extracting Transferrable Robot Skills from Offline Data},
author={Jesse Zhang and Minho Heo and Zuxin Liu and Erdem Biyik and Joseph J Lim and Yao Liu and Rasool Fakoor},
booktitle={8th Annual Conference on Robot Learning},
year={2024},
url={https://openreview.net/forum?id=uEbJXWobif}
}